A WITH clause is an optional clause that precedes the SELECT list in a query. The WITH clause defines one or more common_table_expressions. Each common table expression defines a temporary table, which is similar to a view definition. You can reference these temporary tables in the FROM clause. Each CTE in the WITH clause specifies a table name, an optional list of column names, and a query expression that evaluates to a table . When you reference the temporary table name in the FROM clause of the same query expression that defines it, the CTE is recursive.

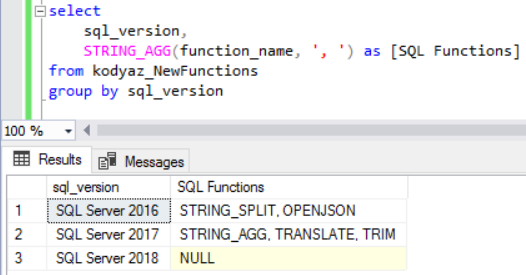
The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause. For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output. The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns.

This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT. SQL gets complex when you have multiple business rules that run how you return record sets. As a coder, you gather business rules that then decide how to structure your SQL statements to ensure that returned results are accurate for reports and applications. These statements get complex when you have several business requirements that must be used to return a data set that helps businesses make decisions.
Some SQL keywords that help you build complex statements include IN, NOT, and LIKE. LIKE uses wildcards, which are used to query similar values, but IN and NOT return precise record sets based on specific values. One of the more heavily used table hints in the SELECT T-SQL statements is the WITH hint. The default transaction isolation level in SQL Server is the READ COMMITTED isolation level, in which retrieving the changing data will be blocked until these changes are committed. In this way, the query will consume less memory in holding locks against that data. In addition to that, no deadlock will occur against the queries, that are requesting the same data from that table, allowing a higher level of concurrency due to a lower footprint.
In other words, the WITH table hint retrieves the rows without waiting for the other queries, that are reading or modifying the same data, to finish its processing. This is similar to the READ UNCOMMITTED transaction isolation level, that allows the query to see the data changes before committing the transaction that is changing it. The transaction isolation level can be set globally at the connection level using the SET TRANSACTION ISOLATION LEVEL T-SQL command, as will see later in this article. A value expression can be a literal value, like a string or numeric value, a mathematical expression, or a column name. Note that it's almost always the case that at least one value expression in a WHERE clause predicate is the name of a column in the table referenced in the operation's FROM clause. The PARTITION BY clause is used to divide the result set from the query into data subsets, or partitions.

If the PARTITION BY clause is not used, the entire result set from the query is the partition that will be used. The window function being used is applied to each partition separately, and the computation that the function performs is restarted for each partition. You define a set of values which determine the partition to divide the query into.

These values can be columns, scalar functions, scalar subqueries, or variables. You might return 1000 records but want to exclude some records within the data set. So far, we've only created SQL statements where you want to include records.

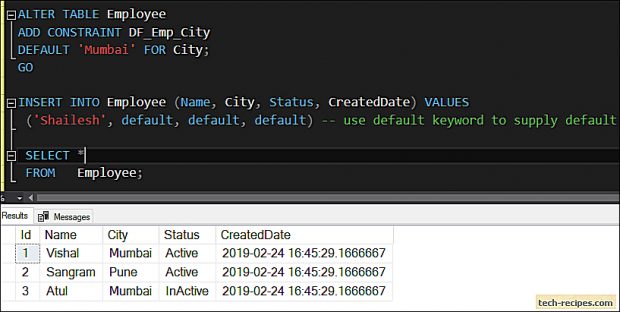
Suppose you want to include records with city values of Atlanta and Miami, but you want to exclude records where the user's first name is Joe. SQL has a NOT operator that excludes those records while still including the others that match the original IN query. The following query gives you an example of the NOT operator. I.e. it filters records from a table as per the condition. A WITH clause contains one or more common table expressions . A CTE acts like a temporary table that you can reference within a single query expression.

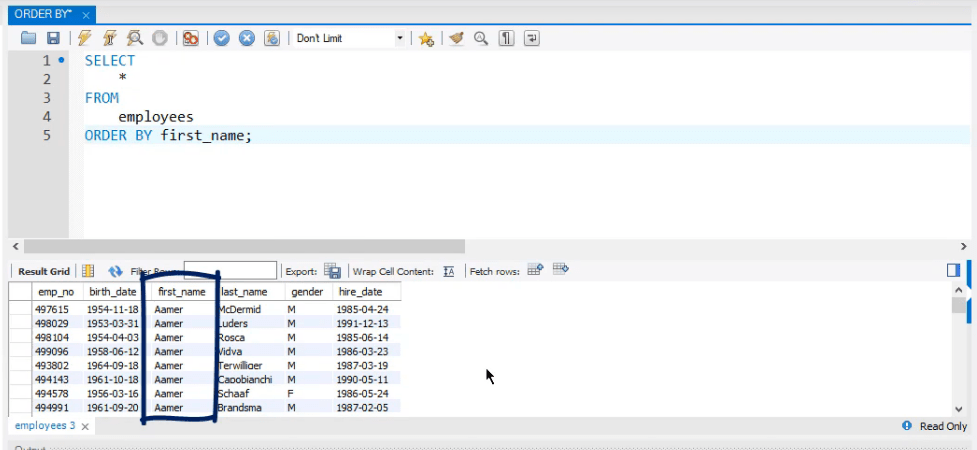
Each CTE binds the results of a subqueryto a table name, which can be used elsewhere in the same query expression, but rules apply. The ORDER BY clause specifies a column or expression as the sort criterion for the result set. If an ORDER BY clause is not present, the order of the results of a query is not defined. Column aliases from a FROM clause or SELECT list are allowed.

If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. When querying multiple tables, use aliases, and employ those aliases in your select statement, so the database doesn't need to parse which column belongs to which table. Note that if you have columns with the same name across multiple tables, you will need to explicitly reference them with either the table name or alias.

A predicate is a condition expression that evaluates to either true or false. Each predicate must be composed of columns from the primary key or a secondary index. This allows the primary key or a secondary index to be selected to find the rows of the table to use for evaluating the predicate. Where clause is used to fetch a particular row or set of rows from a table. This clause filters records based on given conditions and only those row comes out as result that satisfies the condition defined in WHERE clause of the SQL query. A list of output column names for the WITH clause subquery, separated by commas.

The number of column names specified must be equal to or less than the number of columns defined by the subquery. For a CTE that is non-recursive, the column_name clause is optional. Instead of writing out each member of a set yourself, you can derive a set by following the IN operator with a subquery. A subquery — also known as a nested or inner query — is a SELECT statement embedded within one of the clauses of another SELECT statement.

A subquery can retrieve information from any table in the same database as the table defined in the FROM clause of the "outer" operation. During the execution of the statement in which it is embedded; it runs before the recursive clause and generates the first set of rows from the recursive CTE. These rows are not only included in the output of the query, but also referenced by the recursive clause. The USING clause requires a column list of one or more columns which occur in both input tables. It performs an equality comparison on that column, and the rows meet the join condition if the equality comparison returns TRUE. Because the UNNEST operator returns avalue table, you can alias UNNEST to define a range variable that you can reference elsewhere in the query.

If you reference the range variable in the SELECTlist, the query returns a STRUCT containing all of the fields of the originalSTRUCT in the input table. Release 11g introduced adaptive cursor sharing to further improve the situation. This feature allows the database to cache multiple execution plans for the same SQL statement.

Further, the optimizer peeks the bind parameters and stores their estimated selectivity along with the execution plan. When the cache is subsequently accessed, the selectivity of the current bind values must fall within the selectivity ranges of a cached execution plan to be reused. Otherwise the optimizer creates a new execution plan and compares it against the already cached execution plans for this query. If there is already such an execution plan, the database replaces it with a new execution plan that also covers the selectivity estimates of the current bind values. If not, it caches a new execution plan variant for this query — along with the selectivity estimates, of course. "WHERE" is the keyword that restricts our select query result set and "condition" is the filter to be applied on the results.

HAVING and WHERE are often confused by beginners, but they serve different purposes. WHERE is taken into account at an earlier stage of a query execution, filtering the rows read from the tables. If a query contains GROUP BY, rows from the tables are grouped and aggregated.
After the aggregating operation, HAVING is applied, filtering out the rows that don't match the specified conditions. Therefore, WHERE applies to data read from tables, and HAVING should only apply to aggregated data, which isn't known in the initial stage of a query. Not all columns of the primary key or secondary indexes need to be referenced by a WHERE clause predicate.

When a primary key or secondary index includes more than one column, the administrator has defined them from left to right. For the primary key or a secondary index to be considered for use in evaluating a predicate, at least the left-most column of the key or index must be referenced by the predicate. The primary key or a secondary index is not selected, if the WHERE clause skips the left-most column but refers only to columns defined further to the right. The table hints can be added to the FROM clause of the T-SQL query, affecting the table or the view that is referenced in the FROM clause only. In this lesson we cover the types of conditions you can put in the WHERE clause of any SQL SELECT query.
There are several combinations based on the comparison operator and the data type of the columns in the operation. Notice that this result set doesn't include Maya even though the range provided in the search condition is from A to M. After the column name comes the BETWEEN operator and two more value expressions separated by AND.

Following the WHERE keyword is a value expression which, in most SQL operations, is the name of a column. When referencing a range variable on its own without a specified column suffix, the result of a table expression is the row type of the related table. Value tables have explicit row types, so for range variables related to value tables, the result type is the value table's row type. Other tables do not have explicit row types, and for those tables, the range variable type is a dynamically defined STRUCT that includes all of the columns in the table.
The visibility of a common table expression within a query expression is determined by whether or not you add the RECURSIVE keyword to theWITH clause where the CTE was defined. You can learn more about these differences in the following sections. If this keyword is not present, you can only include non-recursive common table expressions .

If this keyword is present, you can use both recursive andnon-recursive CTEs. The INTERSECT operator returns rows that are found in the result sets of both the left and right input queries. Unlike EXCEPT, the positioning of the input queries does not matter.

SELECT AS STRUCT can be used in a scalar or array subquery to produce a single STRUCT type grouping multiple values together. Scalar and array subqueries are normally not allowed to return multiple columns, but can return a single column with STRUCT type. Query statements scan one or more tables or expressions and return the computed result rows. This topic describes the syntax for SQL queries in BigQuery.
Why We Use Having Clause In Sql The SQL WHERE clause is used to specify a condition while fetching the data from a single table or by joining with multiple tables. If the given condition is satisfied, then only it returns a specific value from the table. You should use the WHERE clause to filter the records and fetching only the necessary records. WHERE Clause in MySQL is a keyword used to specify the exact criteria of data or rows that will be affected by the specified SQL statement.
The WHERE clause can be used with SQL statements like INSERT, UPDATE, SELECT, and DELETE to filter records and perform various operations on the data. In both the SumByRows and SumByRange columns the OVER clause is identical with the exception of the ROWS/RANGE clause. In the SumByRows column, the value is calculated using the ROWS clause, and we can see that the sum of the current row is the current row's Salary plus the prior row's total. However, the RANGE clause works off of the value of the Salary column, so it sums up all rows with the same or lower salary. This results in the SumByRange value being the same value for all rows with the same Salary. You can compose queries using Metabase's graphical interface to join tables, filter and summarize data, create custom columns, and more.

And with custom expressions, you can handle the vast majority of analytical use cases, without ever needing to reach for SQL. An IN operator allows the specification of two or more expressions to be used for a query search. The result of the condition returns TRUE if the value of the corresponding column equals one of the expressions specified by the IN predicate. The SQL language lets you combine NOT and LIKE to eliminate search results using the same type of logic except records are removed from a data set instead of adding them. For instance, instead of searching for customers in cities that start with "Da," you can exclude customers that are located in those cities. The following SQL statement uses the NOT keyword with the LIKE keyword.
The first SELECT subquery doesn't have a recursive reference to the same CTE_table_name. It returns a result set that is the initial seed of the recursion. This keyword is required if any common_table_expression defined in the WITH clause is recursive. You can only specify the RECURSIVE keyword once, immediately following the WITH keyword, even when the WITH clause contains multiple recursive CTEs.
In general, a recursive CTE is a UNION ALL subquery with two parts. After the WHERE keyword comes a value expression; again, this first value expression is usually the name of a column. Following that is the IN operator, itself followed by a set of data. As mentioned in the introduction, this guide focuses on outlining how to use SQL's BETWEEN and IN operators to filter data.
If you'd like to learn how to use the comparison or IS NULL operators, we encourage you to check out this guide on How To Use Comparison and IS NULL Operators in SQL. Alternatively, if you'd like to learn how to use the LIKE operator to filter data based on a string pattern containing wildcard characters, follow our guide on How To Use Wildcards in SQL. Lastly, if you'd like to learn more about WHERE clauses generally, you may be interested in our tutorial on How To Use WHERE Clauses in SQL. In any SQL operation that reads data from an existing table, you can follow the FROM clause with a WHERE clause to limit what data the operation will affect. WHERE clauses do this by defining a search condition; any row that doesn't meet the search condition is excluded from the operation, but any row that does is included.
The following query finds products whose list price is greater than 3,000 or whose model is 2018. Any product that meets one of these conditions are included in the result set. The following example selects the range variable Coordinate, which is a reference to rows in table Grid. Since Grid is not a value table, the result type of Coordinate is a STRUCT that contains all the columns from Grid. The result set always uses the supertypes of input types in corresponding columns, so paired columns must also have either the same data type or a common supertype. Set operators combine results from two or more input queries into a single result set.